Dados duplicados podem comprometer a integridade e o desempenho do banco de dados. Este artigo explora um método eficaz para excluir linhas duplicadas no MySQL usando a técnica DELETE JOIN. Este guia passo a passo é projetado para técnicos, desenvolvedores e profissionais de TI que priorizam a limpeza dos dados.
Encontrar linhas duplicadas nas tabelas MySQL é um desafio comum que muitos enfrentam. Esta condição pode levar a resultados de consulta imprecisos e a um aumento na carga do sistema. Portanto, a capacidade de excluir linhas duplicadas no MySQL é uma habilidade essencial. Este tutorial irá guiá-lo na resolução deste problema com um método eficiente e comprovado.
Preparando uma Tabela de Dados de Exemplo
Antes de praticar o método de exclusão, você precisa configurar um ambiente de teste. Crie uma tabela chamada duplicate_row com a seguinte estrutura e dados iniciais em seu banco de dados.
CREATE TABLE `duplicate_row` (
`id` int(11) DEFAULT NULL,
`refID` int(11) DEFAULT NULL,
`data` varchar(7) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Em seguida, insira dados de exemplo que contenham valores duplicados na coluna refID.
INSERT INTO `duplicate_row` (`id`, `refID`, `data`) VALUES
(1, 3526, 'aaaaaaa'),
(2, 3527, 'bbbbbbb'),
(3, 3528, 'ccccccc'),
(4, 3529, 'ddddddd'),
(5, 3527, 'eeeeeee'),
(6, 3528, 'fffffff'),
(7, 3527, 'ggggggg');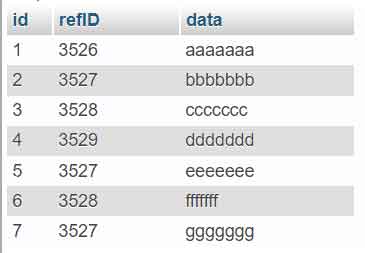
Tutorial: Excluir Linhas Duplicadas no MySQL com DELETE JOIN
O método DELETE JOIN é uma das formas mais eficientes de lidar com duplicatas. Esta técnica funciona ao unir (join) a tabela a si mesma. Isso permite que você identifique e remova linhas redundantes com base em critérios específicos.
- Abra seu aplicativo phpMyAdmin e selecione o banco de dados que contém a tabela
duplicate_row. - Navegue até a aba SQL para executar comandos diretamente.
- Copie e cole a seguinte consulta SQL no campo de texto disponível.
DELETE t1 FROM duplicate_row t1
INNER JOIN duplicate_row t2
WHERE
t1.refID = t2.refID AND
t1.id > t2.id;Importante: A consulta acima manterá a linha com o menor valor de
idpara cada grupo de duplicatas emrefID. As linhas com umidmaior serão excluídas.
- Clique no botão Go para executar o comando.

Uma vez que a consulta seja executada com sucesso, apenas uma linha para cada valor único de refID permanecerá. Por exemplo, para refID 3527, apenas a linha com id=2 é mantida. Este processo é eficaz para excluir linhas duplicadas no MySQL em uma escala razoavelmente grande.
Dicas e Considerações Importantes
Antes de executar qualquer comando de exclusão, sempre crie um backup de sua tabela ou banco de dados primeiro. Esta é uma precaução de segurança padrão. Além disso, certifique-se de ter identificado a(s) coluna(s) correta(s) como referência para a duplicação.
Para cenários mais complexos, como duplicação baseada em várias colunas, você pode adicionar condições à cláusula WHERE. Sempre teste a consulta com uma instrução SELECT primeiro para garantir que os resultados correspondam às suas expectativas. Você também pode consultar a documentação oficial do MySQL para técnicas mais avançadas.
Conclusão
Manter dados limpos e livres de duplicação é uma parte crucial da administração de bancos de dados. O método DELETE JOIN descrito fornece uma solução direta e poderosa. Seguindo os passos práticos acima, você pode resolver prontamente problemas de duplicatas e garantir que a qualidade e o desempenho do seu banco de dados permaneçam otimos.