Si votre base de données contient des lignes de données répétées ou des lignes de données dupliquées, vous pouvez facilement supprimer la duplication en utilisant un script MySQL.
Dans cet article, nous allons apprendre à supprimer les lignes de données dupliquées dans MySQL à l’aide d’un script que nous exécuterons dans phpMyAdmin.
Autres articles intéressants
Préparer un exemple de tableau de données
Avant de commencer, créez un tableau appelé « duplicate_row » avec la structure et les données suivantes :
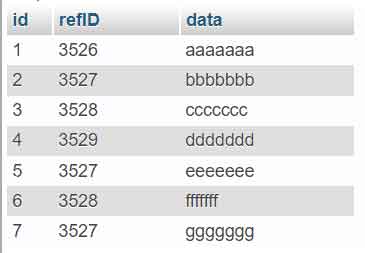
CREATE TABLE `duplicate_row` ( `id` int(11) DEFAULT NULL, `refID` int(11) DEFAULT NULL, `data` varchar(7) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1 PACK_KEYS=0; INSERT INTO `duplicate_row` (`id`, `refID`, `data`) VALUES (1, 3526, 'aaaaaaa'), (2, 3527, 'bbbbbbb'), (3, 3528, 'ccccccc'), (4, 3529, 'ddddddd'), (5, 3527, 'eeeeeee'), (6, 3528, 'fffffff'), (7, 3527, 'ggggggg'); COMMIT;
Supprimer les lignes en double à l’aide de DELETE JOIN
- Ouvrez phpMyAdmin et sélectionnez le nom de la base de données dans la table » duplicate_row « . Cliquez ensuite sur l’onglet » SQL « . Copiez ensuite le script suivant.
DELETE t1 FROM duplicate_row t1 JOIN duplicate_row t2 ON t2.refID = t1.refID AND t2.id < t1.id
- Cliquez ensuite sur le bouton « Aller pour exécuter le script.


- Le script supprimera tous les doublons et conservera la ligne avec le plus petit « id ».
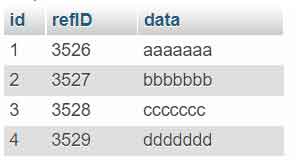
- Pour modifier les critères de suppression, modifiez le script dans la section » ET t2.id < ; t1.id » en fonction de ce que vous souhaitez.
Bonne chance…
J’espère que c’est utile….
