Este artículo discute técnicas prácticas para generar grandes cantidades de datos de prueba aleatorios en una base de datos MySQL. Aprenderás a crear funciones y procedimientos almacenados para llenar automáticamente tablas con miles de filas de datos. Este método es muy útil para pruebas de rendimiento, simulación de carga y desarrollo de aplicaciones que requieren conjuntos de datos realistas.
El desarrollo de aplicaciones basadas en bases de datos requiere pruebas que se asemejen a condiciones reales. Un script de datos aleatorios MySQL es una solución eficiente para crear datos de prueba a gran escala. Esta simulación ayuda a los desarrolladores a medir el rendimiento de la aplicación en varios escenarios. Puedes probar desde condiciones ideales hasta cargas altas.
Esta técnica utiliza procedimientos almacenados y funciones personalizadas de MySQL. Este enfoque proporciona una alta flexibilidad para determinar la cantidad y el formato de los datos. Además, el proceso de llenado de datos se vuelve más rápido y consistente. Ya no se necesitan métodos manuales para crear grandes cantidades de datos de prueba.
Pasos para Crear una Tabla para Datos Aleatorios
Antes de crear el script, primero prepara la tabla de la base de datos. Crea una tabla con una estructura que se adapte a tus necesidades de prueba. El siguiente ejemplo muestra una tabla simple con tres columnas.
CREATE TABLE `random_data` (
`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`column01` VARCHAR(20) NOT NULL,
`column02` VARCHAR(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;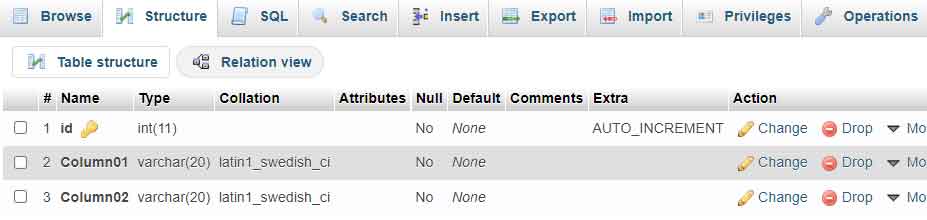
Asegúrate de haber seleccionado la base de datos correcta antes de ejecutar el comando anterior. La columna id se establece como clave principal con incremento automático. De esta manera, cada fila de datos tendrá un identificador único automáticamente.
Creando una Función para Generar Cadenas Aleatorias
El primer paso es crear una función que genere cadenas aleatorias. Esta función será llamada repetidamente por el procedimiento principal. Aquí está la implementación de la función random_string que puedes usar.
DELIMITER $$
CREATE FUNCTION `random_string`(length INT)
RETURNS VARCHAR(255) DETERMINISTIC
BEGIN
DECLARE chars VARCHAR(62) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE result VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < length DO
SET result = CONCAT(result, SUBSTRING(chars, FLOOR(1 + RAND() * 62), 1));
SET i = i + 1;
END WHILE;
RETURN result;
END$$
DELIMITER ;Esta función generará una cadena aleatoria que consta de letras mayúsculas, minúsculas y números. El parámetro length determina la longitud deseada de la cadena. Puedes ajustar el conjunto de caracteres según necesidades específicas.
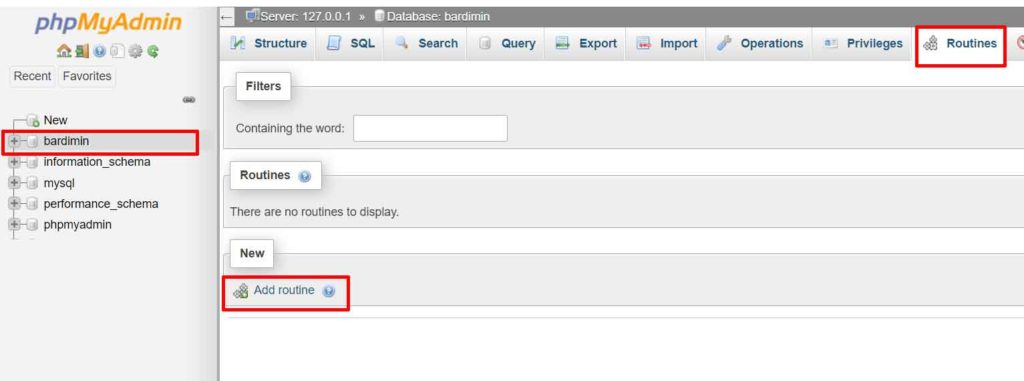
Implementación a través de phpMyAdmin
- Accede a phpMyAdmin y selecciona tu base de datos objetivo.
- Abre la pestaña «Rutinas» en la parte superior de la interfaz.
- Haz clic en el botón «Agregar rutina» para crear una nueva función.
- Selecciona el tipo «FUNCIÓN» e ingresa el código anterior.
- Guarda la función con el nombre
random_string.
Creando un Procedimiento para Inserción Masiva de Datos
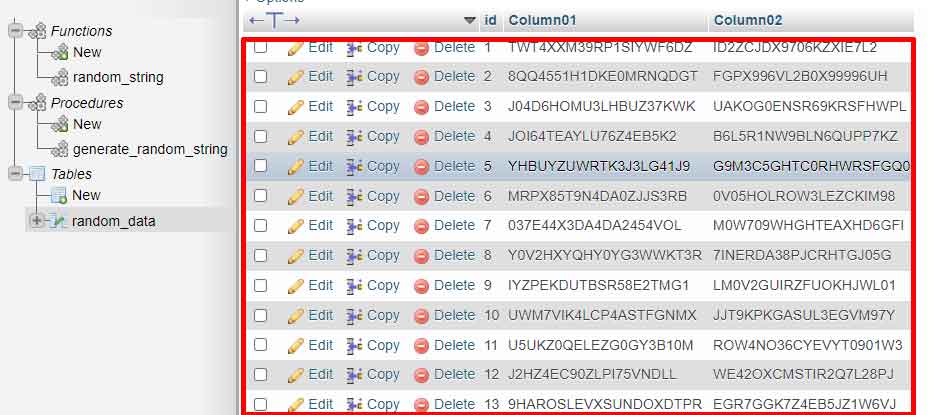
Una vez que la función esté disponible, crea un procedimiento almacenado que realice la inserción masiva de datos. Este procedimiento utiliza bucles para agregar filas repetidamente. Puedes ajustar el número de iteraciones según tus necesidades.
DELIMITER $$
CREATE PROCEDURE `generate_random_data`(IN row_count INT)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < row_count DO
INSERT INTO random_data (column01, column02)
VALUES (random_string(20), random_string(20));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;El procedimiento anterior acepta un parámetro row_count para determinar el número de filas de datos. Por lo tanto, puedes generar datos en cantidades flexibles, desde cientos hasta millones de filas. Este procedimiento llama a la función random_string para cada columna que requiera datos aleatorios.
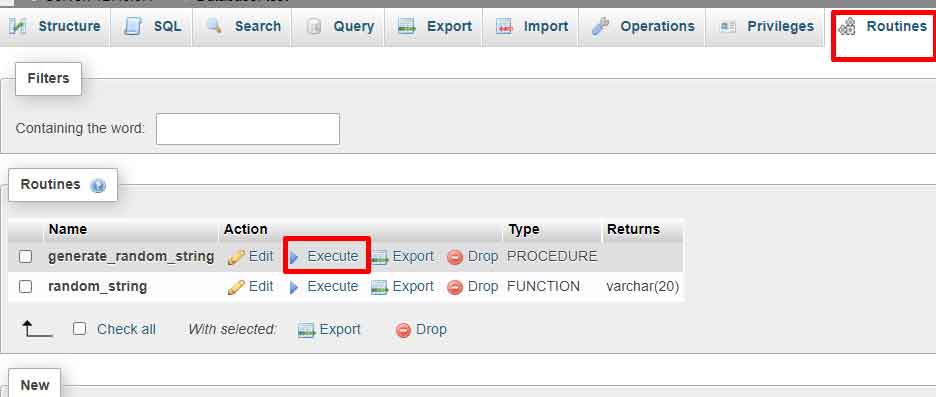
Ejecutando el Procedimiento Almacenado
- En phpMyAdmin, abre nuevamente la pestaña «Rutinas».
- Selecciona el procedimiento
generate_random_datade la lista. - Haz clic en el botón «Ejecutar» junto al nombre del procedimiento.
- Ingresa el número deseado de filas cuando se solicite el parámetro.
- Haz clic en el botón «Continuar» para ejecutar el procedimiento.
Optimización y Consideraciones Técnicas
Para insertar cantidades muy grandes de datos, considera las siguientes optimizaciones:
- Deshabilitar índices temporalmente: Desactiva los índices de la tabla antes de la inserción, luego vuelve a activarlos después de completar. Esto acelera el proceso de inserción masiva.
- Usar una sola transacción: Comienza con
START TRANSACTIONy termina conCOMMIT. Esta técnica reduce la sobrecarga del registro de transacciones. - Procesamiento por lotes: Divide la inserción en varios lotes para evitar tiempos de espera y monitorear el progreso.
- Monitorear recursos: Supervisa el uso de CPU y memoria durante el proceso. Ajusta el tamaño del lote según la capacidad del servidor.
Por ejemplo, para insertar 1 millón de filas de datos, puedes dividirlo en 10 lotes de 100,000 filas cada uno. De esta manera, puedes monitorear el progreso y evitar fallos debido a tiempos de espera.
Siguiendo esta guía, puedes crear un script de datos aleatorios MySQL efectivo para necesidades de prueba. Esta técnica no solo ahorra tiempo, sino que también proporciona datos de prueba más realistas. Para más información sobre procedimientos almacenados, visita la documentación oficial de MySQL. Siempre realiza pruebas en un entorno de desarrollo antes de aplicar en producción.