Si en su base de datos hay filas de datos repetidas o se producen filas de datos duplicadas, puede eliminar la duplicación fácilmente con sólo utilizar un script MySQL.
En este artículo, aprenderemos a eliminar filas de datos duplicados de MySQL mediante un script que ejecutaremos usando phpMyAdmin.
Preparar una tabla de datos de muestra
Antes de empezar, configura una tabla llamada » duplicar_fila » con la siguiente estructura y datos:
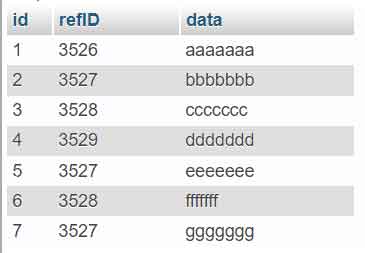
CREATE TABLE `duplicate_row` ( `id` int(11) DEFAULT NULL, `refID` int(11) DEFAULT NULL, `data` varchar(7) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1 PACK_KEYS=0; INSERT INTO `duplicate_row` (`id`, `refID`, `data`) VALUES (1, 3526, 'aaaaaaa'), (2, 3527, 'bbbbbbb'), (3, 3528, 'ccccccc'), (4, 3529, 'ddddddd'), (5, 3527, 'eeeeeee'), (6, 3528, 'fffffff'), (7, 3527, 'ggggggg'); COMMIT;
Otros artículos interesantes
Eliminar filas duplicadas mediante DELETE JOIN
- Abra phpMyAdmin y seleccione el nombre de la base de datos de la tabla » duplicate_row». A continuación, haga clic en la pestaña » SQL «. A continuación, copie el siguiente script.
DELETE t1 FROM duplicate_row t1 JOIN duplicate_row t2 ON t2.refID = t1.refID AND t2.id < t1.id
- Then click the “ Go ” button to run the script.


- El script eliminará todas las filas duplicadas y mantendrá la fila con el «id» más pequeño.
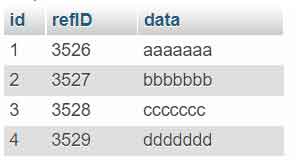
- Para cambiar el criterio de borrado, cambia el script en la » Sección AND t2.id < t1.id » según lo que quieras.
Suerte…
Espero que sea útil….