Los datos duplicados pueden comprometer la integridad y el rendimiento de la base de datos. Este artículo explora un método efectivo para eliminar filas duplicadas en MySQL utilizando la técnica DELETE JOIN. Esta guía paso a paso está diseñada para técnicos, desarrolladores y profesionales de TI que priorizan la limpieza de los datos.
Encontrar filas duplicadas en las tablas de MySQL es un desafío común al que muchos se enfrentan. Esta condición puede llevar a resultados de consultas inexactos y a una mayor carga del sistema. Por lo tanto, la capacidad de eliminar filas duplicadas en MySQL es una habilidad esencial. Este tutorial te guiará para resolver este problema con un método eficiente y probado.
Preparar una Tabla de Datos de Ejemplo
Antes de practicar el método de eliminación, necesitas configurar un entorno de prueba. Crea una tabla llamada duplicate_row con la siguiente estructura y datos iniciales en tu base de datos.
CREATE TABLE `duplicate_row` (
`id` int(11) DEFAULT NULL,
`refID` int(11) DEFAULT NULL,
`data` varchar(7) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;A continuación, inserta datos de ejemplo que contengan valores duplicados en la columna refID.
INSERT INTO `duplicate_row` (`id`, `refID`, `data`) VALUES
(1, 3526, 'aaaaaaa'),
(2, 3527, 'bbbbbbb'),
(3, 3528, 'ccccccc'),
(4, 3529, 'ddddddd'),
(5, 3527, 'eeeeeee'),
(6, 3528, 'fffffff'),
(7, 3527, 'ggggggg');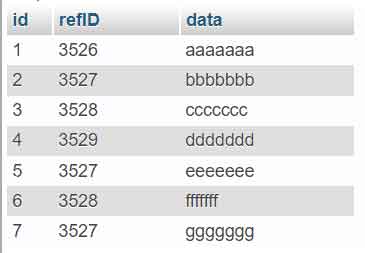
Tutorial: Eliminar Filas Duplicadas en MySQL con DELETE JOIN
El método DELETE JOIN es una de las formas más eficientes de manejar duplicados. Esta técnica funciona al unir (join) la tabla consigo misma. Esto te permite identificar y eliminar filas redundantes según criterios específicos.
- Abre tu aplicación phpMyAdmin y selecciona la base de datos que contiene la tabla
duplicate_row. - Navega a la pestaña SQL para ejecutar comandos directamente.
- Copia y pega la siguiente consulta SQL en el campo de texto disponible.
DELETE t1 FROM duplicate_row t1
INNER JOIN duplicate_row t2
WHERE
t1.refID = t2.refID AND
t1.id > t2.id;Importante: La consulta anterior conservará la fila con el valor de
idmás pequeño para cada grupo duplicado enrefID. Las filas con unidmayor serán eliminadas.
- Haz clic en el botón Go para ejecutar el comando.

Una vez que la consulta se ejecute con éxito, solo quedará una fila por cada valor único de refID. Por ejemplo, para refID 3527, solo se conservará la fila con id=2. Este proceso es efectivo para eliminar filas duplicadas en MySQL a una escala razonablemente grande.
Consejos y Consideraciones Importantes
Antes de ejecutar cualquier comando de eliminación, siempre crea una copia de seguridad (backup) de tu tabla o base de datos primerro. Esta es una precaución de seguridad estándar. Además, asegúrate de haber identificado la(s) columna(s) correcta(s) como referencia para la duplicación.
Para escenarios más complejos, como la duplicación basada en múltiples columnas, puedes agregar condiciones a la cláusula WHERE. Siempre prueba la consulta con una declaración SELECT primero para asegurarte de que los resultados coincidan con tus expectativas. También puedes consultar la documentación oficial de MySQL para técnicas más avanzadas.
Conclusión
Mantener datos limpios libres de duplicación es una parte crucial de la administración de bases de datos. El método DELETE JOIN descrito proporciona una solución directa y poderosa. Siguiendo los pasos prácticos anteriores, puedes abordar rápidamente los problemas de duplicados y garantizar que la calidad y el rendimiento de tu base de datos se mantengan óptimos.