In this article, we will learn to remove duplicate data rows from MySQL by using a script that we will run using phpMyAdmin.
Prepare sample data table
Before we start, set up a table named ” duplicate_row ” with the following structure and data:
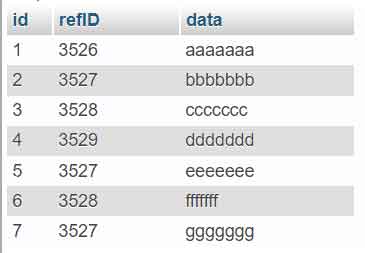
CREATE TABLE `duplicate_row` ( `id` int(11) DEFAULT NULL, `refID` int(11) DEFAULT NULL, `data` varchar(7) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1 PACK_KEYS=0; INSERT INTO `duplicate_row` (`id`, `refID`, `data`) VALUES (1, 3526, 'aaaaaaa'), (2, 3527, 'bbbbbbb'), (3, 3528, 'ccccccc'), (4, 3529, 'ddddddd'), (5, 3527, 'eeeeeee'), (6, 3528, 'fffffff'), (7, 3527, 'ggggggg'); COMMIT;
Other Interesting Articles
Remove duplicate rows using DELETE JOIN
- Open phpMyAdmin and select the database name from the ” duplicate_row ” table . Then click the “ SQL ” tab . Then copy the following script.
DELETE t1 FROM duplicate_row t1 JOIN duplicate_row t2 ON t2.refID = t1.refID AND t2.id < t1.id
- Then click the “ Go ” button to run the script.


- The script will remove all duplicate rows and keep the row with the smallest “id.
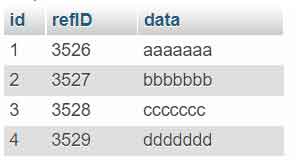
- To change the deletion criteria, change the script in the “ AND section t2.id < t1.id ” according to what you want.
Good luck…
Hope it is useful….